RabbitMQ 知识库
RabbitMq
基础
略咯~~ 网上很多的
队列模式
RabbitMq队列具备两种模式:default和lazy。在队列声明的时候可以通过x-queue-mode参数来设置队列的模式,取值为default和lazy。
RabbitMQ从3.6.0版本开始引入了惰性队列的概念,即将接受到的消息直接存入文件系统中,而在消费者消费到相应的消息时才会被加载到内存中,它的一个重要的设计目标是能够支持更长的队列,即支持更多的消息存储。惰性队列虽然减少了内存的消耗,但是增加了I/O的使用,因此对于持久化的消息,本身就不可避免磁盘I/O,使用惰性队列是较佳的选择。要注意的是,如果惰性队列中存储的是非持久化的消息,重启之后消息一样会丢失。
默认情况下,消息会先存放在内存中,即使是持久化消息也会在内存中驻留一份备份,这部分是由Mq内部的存储结构决定的,后面有写~ 当mq需要释放内存的时候,会将内存中的消息换页(page)到磁盘中,这个操作比较耗时,也会阻塞队列的操作,无法接受新的消息,严重的话甚至会长达几分钟。
官方说明文档:
https://www.rabbitmq.com/lazy-queues.html
惰性队列和普通队列相比,只有很小的内存开销。这里很难对每种情况给出一个具体的数值,但是我们可以类比一下:当发送1千万条消息,每条消息的大小为1KB,并且此时没有任何的消费者,那么普通队列会消耗1.2GB的内存,而惰性队列只消耗1.5MB的内存。
据官网测试数据显示,对于普通队列,如果要发送1千万条消息,需要耗费801秒,平均发送速度约为13000条/秒。如果使用惰性队列,那么发送同样多的消息时,耗时是421秒,平均发送速度约为24000条/秒。出现性能偏差的原因是普通队列会由于内存不足而不得不将消息换页至磁盘。如果有消费者消费时,惰性队列会耗费将近40MB的空间来发送消息,对于一个消费者的情况,平均的消费速度约为14000条/秒。
镜像队列 vs 仲裁队列
以下围绕同步模型和性能。
镜像队列
RabbitMQ的集群在默认模式下,队列实例只存在于一个节点上,既不能保证该节点崩溃的情况下队列还可以继续运行,也不能线性扩展该队列的吞吐量。虽然RabbitMQ的队列实际只会在一个节点上,但元数据可以存在于各个节点上。举个例子来说,当创建一个新的交换器时,RabbitMQ会把该信息同步到所有节点上,这个时候客户端不管连接到哪个RabbitMQ节点,都可以访问到这个新的交换器,也就能找到交换器下的队列:
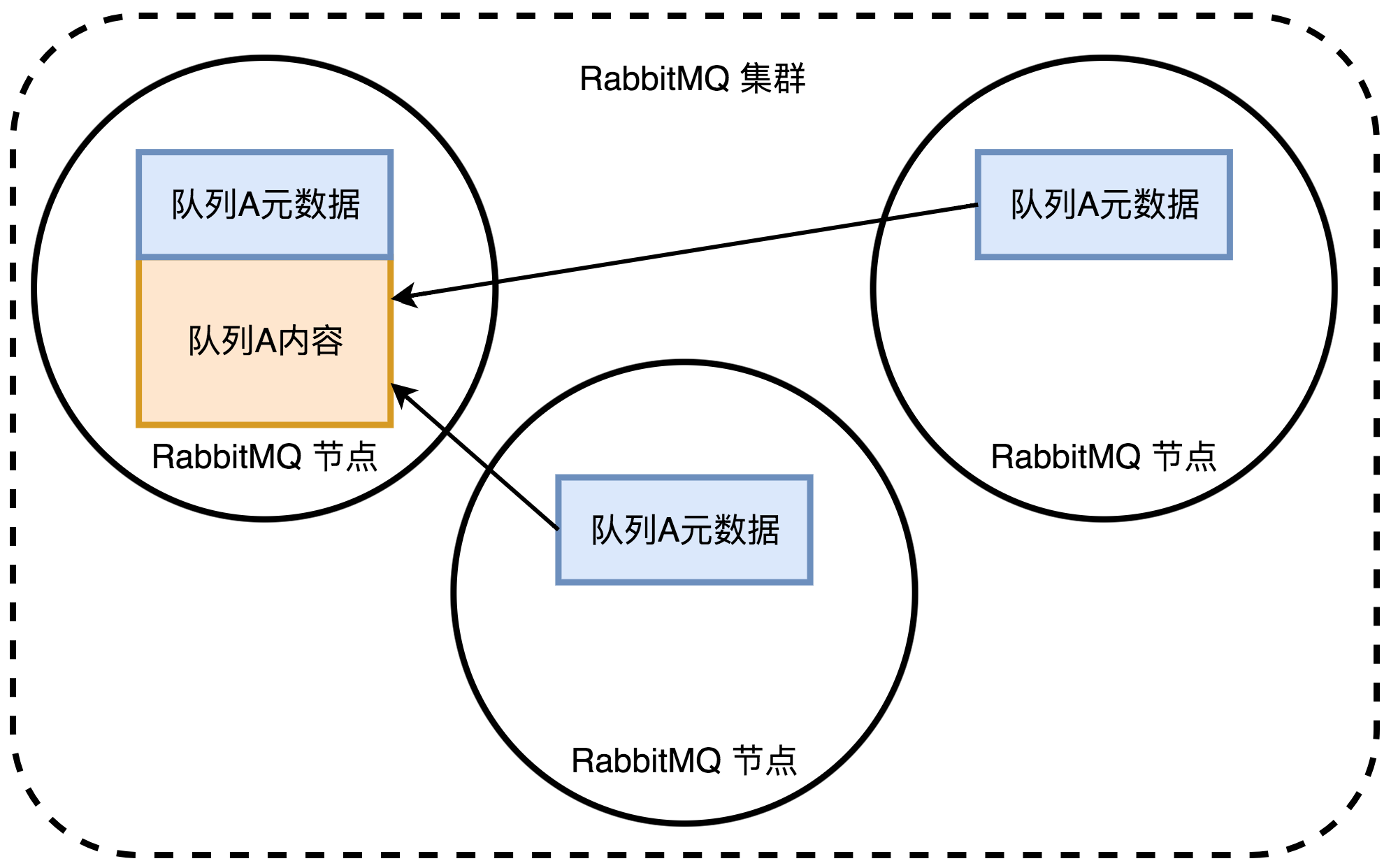
RabbitMQ内部的元数据主要有:
- 队列元数据:队列名称和属性
- 交换器元数据:交换器名称,类型和属性
- 绑定元数据:路由信息
尽管交换器和绑定关系能够在单点故障问题上幸免于难,但是队列和其上存储的消息却不行,它们仅存在于单个节点上。引入镜像队列的机制,可以将队列镜像到集群中的其它Broker节点之上,如果集群中的一个节点失效了,队列能够自动地切换到镜像中的另一个节点上以保证服务的可用性。通常情况下,针对每一个配置镜像的队列都包含一个主拷贝和若干个从拷贝,相应架构如下:
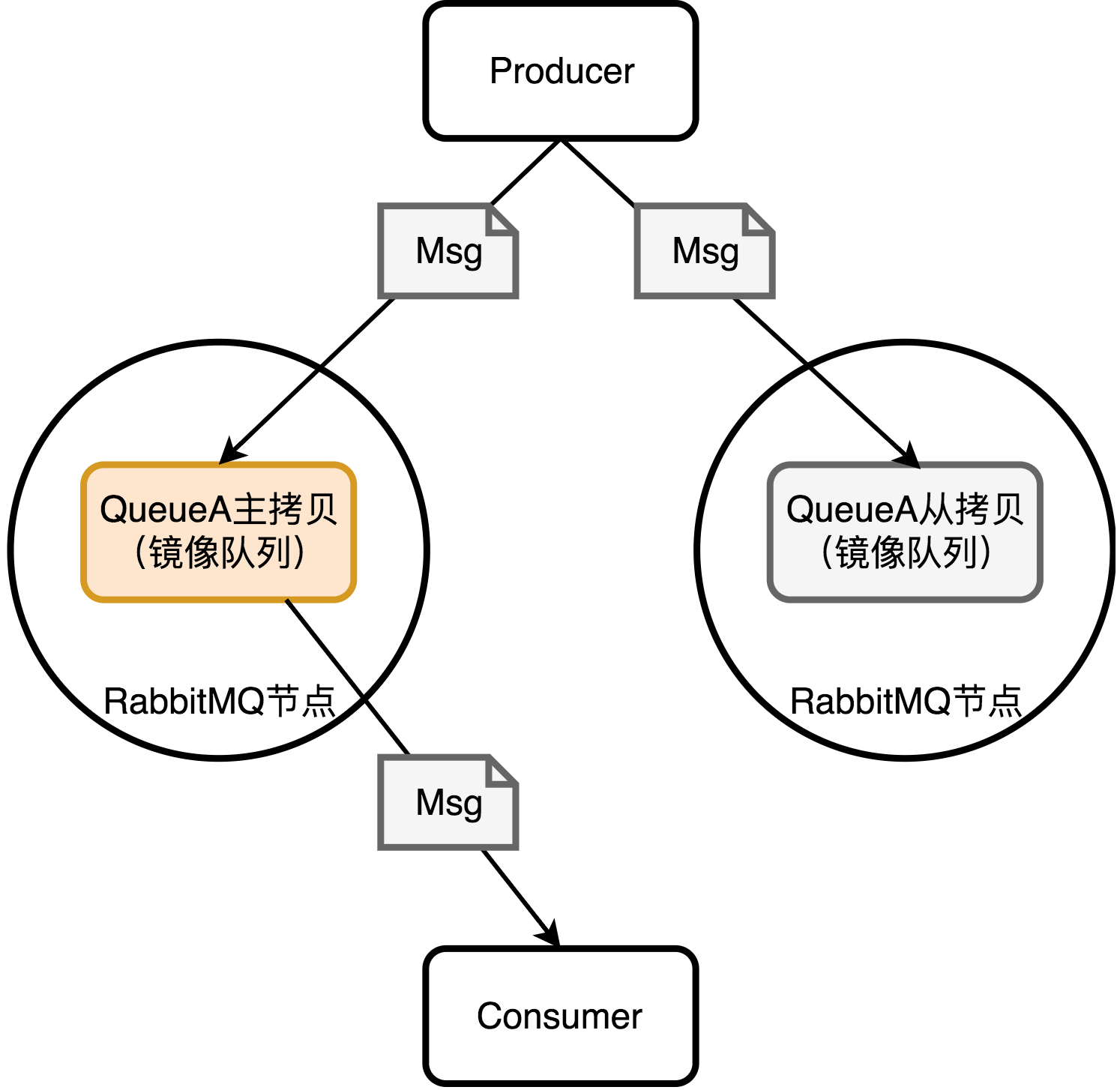
除了发送消息外的所有动作都只会向主拷贝发送,然后再由主拷贝将命令执行的结果广播给各个从拷贝,从拷贝实际只是个冷备(默认的情况下所有RabbitMQ节点上都会有镜像队列的拷贝),如果使用消息确认模式,RabbitMQ会在主拷贝和从拷贝都安全的接受到消息时才通知生产者。从这个结构上来看,如果从拷贝的节点挂了,实际没有任何影响,如果主拷贝挂了,那么会有一个重新选举的过程,这也是镜像队列的优点,除非所有节点都挂了,才会导致消息丢失。重新选举后,RabbitMQ会给消费者一个消费者取消通知(Consumer Cancellation),让消费者重连新的主拷贝。
实现原理
不同于普通的非镜像队列,镜像队列的实现结构如下: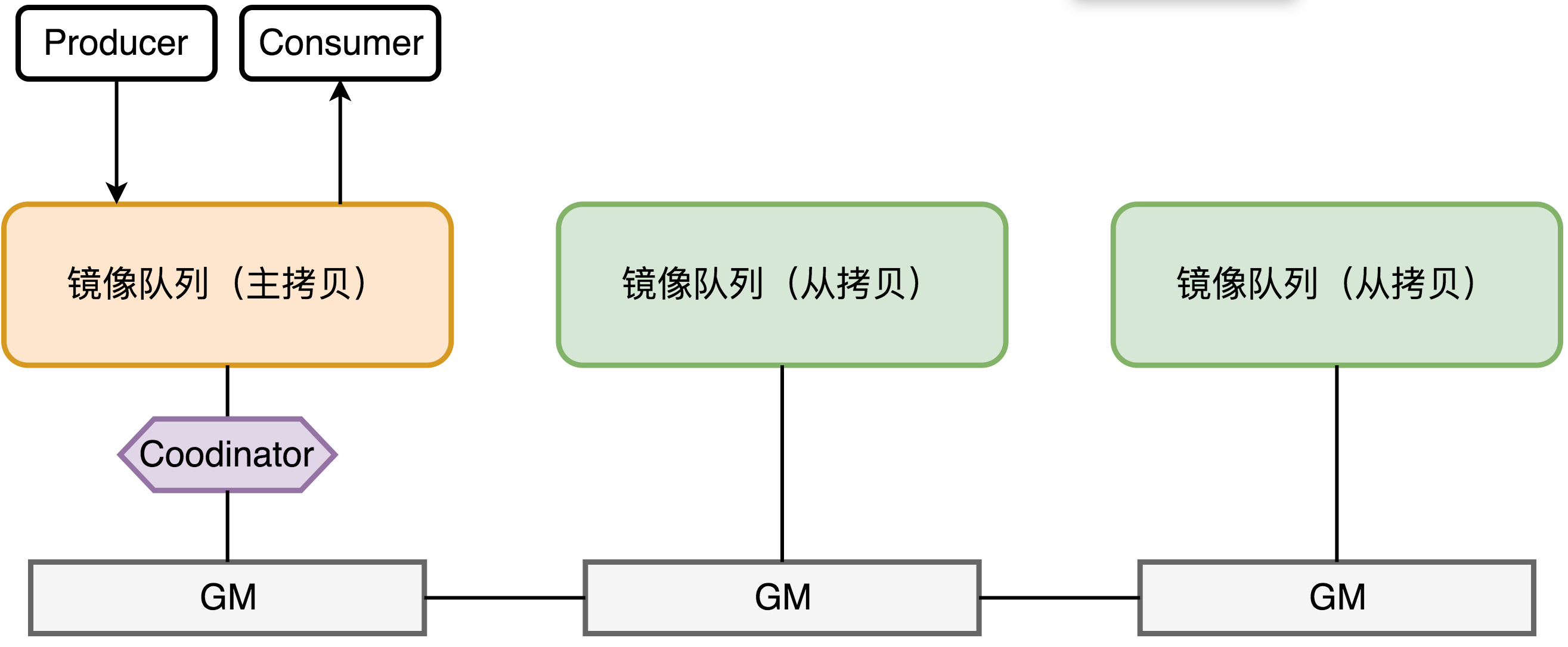
所有对镜像队列主拷贝的操作,都会通过GM同步到各个slave节点,Coodinator负责组播结果的确认。GM是一种可靠的组播通信协议,该协议能够保证组播消息的原子性,即保证组内的存活节点要么都收到消息要么都收不到。
GM的组播并不是由master来负责通知所有slave的(目的是为了避免master压力过大,同时避免master失效导致消息无法最终ack),RabbitMQ把所有节点组成一个链表,每个节点都会监控位于自己左右两边的节点,当有节点新增时,相邻的节点保证当前广播的消息会复制到新节点上;当有节点失效时,相邻的节点会接管以保证本次广播的消息会复制到所有的节点。操作命令由master发起,也由master最终确认通知到了所有的slave,而中间过程则由slave接力的方式进行消息传播。
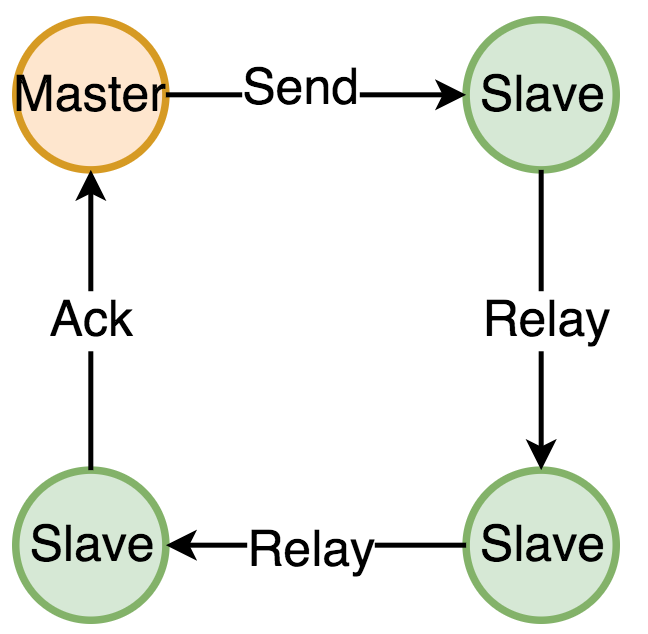
镜像队列性能低于应有的速度,使用leader 队列 和一个以上的镜像队列,读写操作都经过leader队列,同时将所有的命令复制到镜像队列里,一旦所有的镜像队列都持有这个消息,leader队列才会发送confirm。 一旦过程中leader下线了,一个镜像队列将会成为leader使得整个队列依然可用。
在节点与节点之间有一个Inter-node Communication Buffer,用来临时缓存尚未同步的消息, 在某些情况下,节点间的通信量可能非常大,并且会耗尽缓存区的容量,默认配置是128M 。如果要修改可以使用环境变量。当缓存区耗尽的时候会导致节点阻塞。
RABBITMQ_DISTRIBUTION_BUFFER_SIZE=192000 #直接设置值
RABBITMQ_SERVER_ADDITIONAL_ERL_ARGS="+zdbbl 192000" #增加值 单位: 千字节当缓冲区处在满负载的情况下,节点会记录一个警告,提到一个负载严重的端口
2019-04-06 22:48:19.031 [warning] <0.242.0> rabbit_sysmon_handler busy_dist_port <0.1401.0>
具体官方描述 : https://www.rabbitmq.com/runtime.html#distribution-buffer
问题1: 当broker重新上线的话需要面临一个问题: 是否同步镜像,如果同步了,原本队列中的消息就会丢失,同步意味着将当前消息从leader复制到镜像。
问题2: 接上个问题, 同步过程会阻塞整个队列,导致队列不可用。如果队列很短影响不大,producer可以重新发送那些在同步过程中被拒绝的消息。但是当队列很长的话,影响就很大了。
默认情况下会自动同步,如果选择不同步镜像的话:所有新消息都会得到复制,但是现有消息不会,也就是说冗余会减少,会存在更大的消息丢失的可能。同时滚动更新也会成为问题,因为重启broker会丢失所有数据需要同步来恢复数据冗余。
仲裁队列
基于raft 算法的实现,仲裁队列比镜像队列更安全,并且吞吐量更高。那么,这是什么意思呢?
每个仲裁队列是一个复制队列。它有一个Leader和多个Follower。具有5的复制因子的仲裁队列将由五个复制的队列组成:领导者和四个跟随者。每个复制的队列将托管在不同的节点上。
客户(发布者和消费者)始终与Leader 进行交互,Leader然后将所有命令(写入,读取,确认等)复制到跟随者。追随者根本不与客户互动。它们仅出于冗余目的而存在,从而在Broker发生故障,宕机时,另一个Broker上的跟随者副本将被选为Leader,并且服务将继续。
仲裁队列之所以有其名称,是因为所有操作(消息复制和领导者选举)都需要多数副本(称为仲裁)才能达成一致。发布者发送消息时,只有大多数副本将消息写入磁盘后,队列才能确认它。这意味着缓慢的少数群体不会降低整个队列的速度。同样,只有在多数人同意的情况下才能选举领导者,这可以防止两个领导者在发生网络分区时接受消息。因此,仲裁队列的重点是可用性的一致性。
仲裁队列的建议副本数是群集节点的仲裁数(但不少于三个)。
要声明仲裁队列,请将x-queue-type queue参数设置为quorum (默认值为classic)
性能特点
仲裁队列被设计为以延迟为代价来交换吞吐量,并且已经过测试,并与几种消息大小的3、5和7节点配置中的持久经典镜像队列进行了比较。在同时使用使用者acks和发布者的情况下,确认已观察到仲裁队列与经典镜像队列具有相等或更大的吞吐量。
由于仲裁队列会在执行任何操作之前将所有数据持久保存到磁盘,因此建议使用尽可能快的磁盘。仲裁队列还受益于使用较高预取值的使用者,以确保在确认流经系统并允许消息及时传递的同时,不会使使用者感到饥饿。
由于仲裁队列的磁盘I / O繁忙特性,其吞吐量随着消息大小的增加而降低。
就像镜像队列一样,仲裁队列也受群集大小的影响。仲裁队列中的副本越多,通常其吞吐量就越低,因为必须做更多的工作来复制数据并达成共识。
具体可以看官方描述:https://www.rabbitmq.com/quorum-queues.html
两种队列的区别
| 特性 | 镜像队列 | 仲裁队列 |
|---|---|---|
| 非持久性队列 | yes | no |
| 排他性 | yes | no |
| 每条消息的持久性 | per message | always |
| 成员变更 | automatic | manual |
| Message TTL | yes | no |
| Queue TTL | yes | yes |
| Queue length limits | yes | yes (except x-overflow: reject-publish-dlx) |
| Lazy队列 | yes | partial (see Memory Limit) |
| 优先级消息 | yes | no |
| 消费者优先级 | yes | yes |
| DLE | yes | yes |
| Adheres to policies | yes | partial (dlx, queue length limits) |
| 对内存 内存预警 做出反应 | yes | partial (truncates log) |
| 处理消费失败信息 | no | yes |
| 全局的QOS值 | yes | no |
DLE(Dead-letter-exchange )
一些消息在被broker接收的时候就无法被投递或者处理, 这些信息被称为dead message 。
被认为dead message 的情况:
- 不被消费者认可消息被否定确认,使用
channel.basicNack或channel.basicReject,并且此时requeue属性被设置为false。 - TTL过期
- 队伍达到了最大容量
死信队列应用场景
一般用在较为重要的业务队列中,确保未被正确消费的消息不被丢弃,一般发生消费异常可能原因主要有由于消息信息本身存在错误导致处理异常,处理过程中参数校验异常,或者因网络波动导致的查询异常等等,当发生异常时,当然不能每次通过日志来获取原消息,然后让运维帮忙重新投递消息。通过配置死信队列,可以让未正确处理的消息暂存到另一个队列中,待后续排查清楚问题后,编写相应的处理代码来处理死信消息,这样比手工恢复数据要好太多了。
用AlternateExchange中收集不可路由的消息
不可路由消息会导致:
- 返回到一个不断重新发送他们的损坏的应用程序
- Mq被恶意活动攻击导致失去响应
- 关键数据丢失
可以通过基于消息头的的mandatory flag来设置如何处理: true 则原路返回,false 则是静默删除,log可以记录返回的消息但是log无法提供无法访问的exchange或queue 的信息
使用AlternateExchange来捕捉不可路由的消息,主交换器上的 mandatory flag需要set,备用交换器上不能,主交换器将消息转发到备用交换器上,备用交换器将消息发送给备用队列( 他们之间的绑定方式是fanot),将不可路由消息交给专门的consumer处理吧。
What happens when the mandatory flag is set with an alternate exchange?
There is still a chance that messages won’t be routed if an alternate exchange is provided. The service may be unreachable, or the alternate queue may not be specified correctly. You might accidentally specify a non-existent exchange as well.
当消息路由到备用交换的时候,RabbitMq将把消息标记为已交付。
HA方案
默认情况下,queue可以认为是只存在于它被声明的那个节点中,但是broker和binding可以认为存在于集群中的所有节点中. 可以通过镜像的方式,将queue复制到其它的节点中,以此来提高可用性
- 镜像队列之间彼此形成了一主多从的关系,当主镜像队列因为某些原因消失时,一个从镜像自动被推选为主镜像
- 不论客户端连接到哪个结点,它都将连接到主镜像队列中,所有队列的操作也都是通过主镜像队列来完成,这样就保证了队列的FIFO特性
- 发布到主镜像队列中的消息将会被自动镜像到所有的从镜像中
- 如果主镜像中的消息确认已经被消费了,那么从镜像会自动将该消息删除
- 这种镜像的方式并不能将流量分散到各个节点,因为每个节点做的事情是一样的,但是它提高了可用性,如果主镜像队列因为某些原因消失了,那么从镜像可以自动升级为主镜像,保证了队列的可用性
负载均衡
Rabbitmq队列是不存在于多个节点上的结构,假设有一个负载平衡的、 HA (高可用性) RabbitMQ 集群,如下所示:
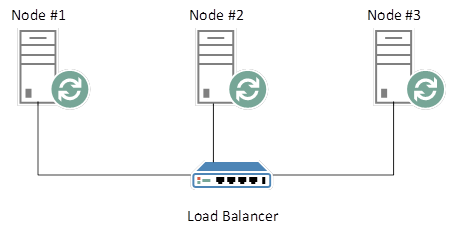
节点1-3在彼此之间进行复制,以便在每个节点之间同步所有符合 HA策略的队列的快照。假设我们登录到 RabbitMQ 管理控制台并创建一个新的 ha 配置的队列。我们的负载均衡器是以循环的方式配置的,在这个实例中,为了方便起见,我们被定向到 Node # 2。我们的新 Queue 是在 Node # 2上创建的。注意: 可以显式选择您希望 Queue 驻留的节点,但是为了本示例的目的,我们忽略这一点。
现在,我们的新 Queue“ NewQueue”存在于 Node # 2中。我们的 HA 策略开始生效,Queue 在所有节点上复制。我们开始向 Queue 添加消息,这些消息也在每个节点之间进行复制。本质上,是获取 Queue 的一个快照,并且在不确定的时间段过去之后在每个节点上复制该快照(当 Queue 的状态发生更改时,它实际上作为一个异步后台任务的发生)。
RabbitMQ 队列是一种单一结构。它只存在于创建它的节点上,与 HA 策略无关。队列总是它自己的主人,并且拥有0…n个从属队列组成。根据上面的示例,节点 # 2上的“ NewQueue”是 Master-Queue,因为这是创建 Queue 的节点。它包含2个从队列-它的对应节点 # 1和 # 3。让我们假设 Node # 2由于某种原因而死亡; 假设整个服务器都关闭了。以下是“ NewQueue”将会发生的情况。
- 节点 # 2不返回心跳,并且被认为是从集群上掉线了
- 主队列不再可用(它随节点 # 2一起死亡)
- RabbitMQ 将 Node # 1或 # 3上的“ NewQueue”从属实例提升为 master
这是 RabbitMQ 中的标准 HA 行为。现在让我们看一下缺省场景,其中所有3个节点都是活的并且运行良好,节点 # 2上的“ NewQueue”实例仍然是主节点。
- 我们连接到 RabbitMQ,目标是“ NewQueue”
- 我们的负载均衡器基于轮循确定一个合适的 Node
- 我们被定向到一个合适的节点(比如说,节点 # 3)
- RabbitMQ 确定“ NewQueue”主节点在 Node # 2上
- 我们成功地连接到“ NewQueue”的主实例
尽管我们的队列在每个 HA 节点上复制,但是每个 Queue 只有一个可用的实例,并且它驻留在创建它的节点上,或者在失败的情况下,提升为 master 的实例。在这种情况下,RabbitMQ 可以方便地将我们路由到该节点:
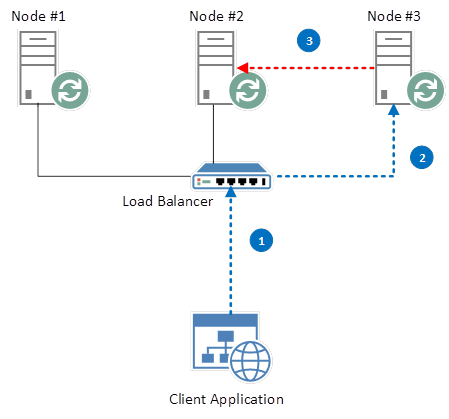
糟糕的是,为了到达目标Queue所在的Node,我们需要额外的网络跳转。按照上面的例子中,有3个节点和一个均衡的负载均衡器,我们将在大约66% 的请求上产生额外的网络跳转。每三个请求中只有一个(假设在任何三个唯一请求的分组中,我们被定向到不同的节点)将导致我们的请求被定向到正确的节点。
为了确保每个请求都被路由到正确的节点,我们有两个选择:
- 显式连接到目标 Queue 所在的节点
- 在节点之间尽可能均匀地分布队列
这两种解决方案都会立即引发问题。在第一个选择中,客户机应用程序必须知道 RabbitMQ 集群中的所有节点,并且还必须知道每个主队列驻留在哪里。如果一个 Node 宕机了,我们的应用程序怎么知道?更不用说这种设计打破了单一责任原则,提高了应用程序中的耦合级别。
第二个解决方案提供了一种设计,其中队列不链接到单个节点。基于我们的“ NewQueue”示例,我们不会简单地在单个节点上实例化一个新的 Queue。相反,在一个3节点的场景中,我们可以实例化3个队列; “ NewQueue1”、“ NewQueue2”和“ NewQueue3”,其中每个队列在一个单独的节点上实例化。
例如,我们的客户端应用程序现在可以实现一个简单的随机化函数,选择上面的队列之一并显式地连接到它。在网络应用程序中,给定3个单独的 HTTP 请求,每个请求将针对上面的队列中的一个,并且没有队列会在所有3个请求中多于一次。现在,我们已经在集群中实现了合理的负载均衡,而没有使用传统的负载均衡器
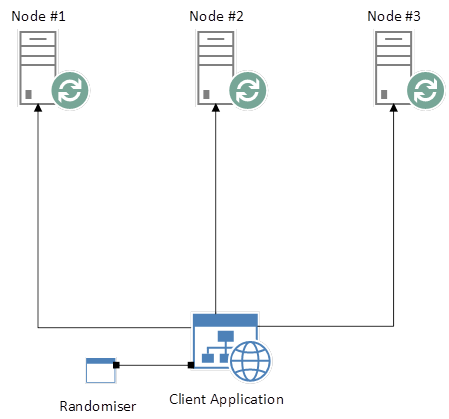
但是我们仍然面临同样的问题; 我们的客户端应用程序需要知道队列驻留在哪里。所以让我们进一步研究解决方案,这样我们就可以避免这个缺点
首先,我们需要提供描述 RabbitMQ 基础结构的映射元数据。具体地说,队列所在的位置。这应该是弹性数据源,如数据库或缓存,而不是平面文件,因为多个数据源(至少是2个)可以并发地访问这些数据。
现在引入一个总是在线的服务,轮询 RabbitMQ,确定节点是否是活的。新队列也应该在这个服务中注册,它应该保持一个最新的注册表,提供关于节点及其队列的元数据:
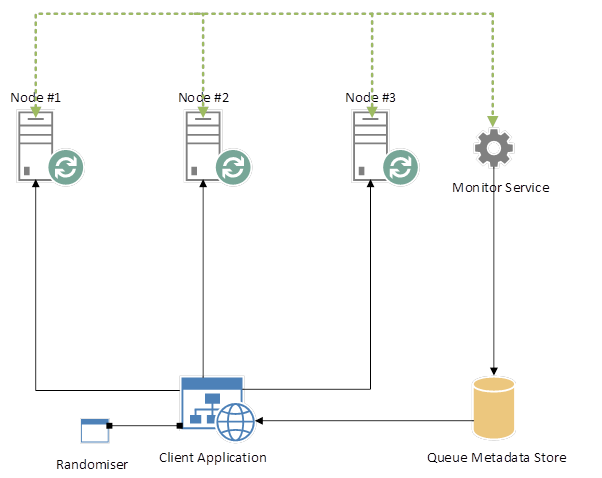
在初始加载时,我们的客户端应用程序应该轮询这个服务并检索 RabbitMQ 元数据,然后为传入的请求保留这些元数据。如果请求由于节点受损而失败,客户机应用程序可以轮询队列元数据存储,返回最新的 RabbitMQ 元数据,并将消息重新路由到工作节点。
参考文章:
https://insidethecpu.com/2014/11/17/load-balancing-a-rabbitmq-cluster/comment-page-1/
https://liqul.github.io/blog/rabbitmq-load-balancing/
https://honeypps.com/mq/rabbitmq-load-balance-3-keepalived-haproxy/
联邦机制
联邦机制的实现,依赖于RabbitMQ的Federation插件,该插件的主要目标是为了RabbitMQ可以在多个 Broker节点或者集群中进行消息的无缝传递。下面先假设一种场景,BrokerA服务部署在上海,BrokerB服务部署在北京。来自上海的ClientA向BrokerA的exchangeA发送消息网络延迟很小,但是北京的ClientB向BrokerA的exchangeA发送消息那么将会面临网络延迟的问题。Federation机制则可以帮助我们解决这个问题。
首先在BrokerA的exchangeA上与北京的BrokerB建立一条单向的Federation Link。此时Federation插件会在BrokerB上建立一个同名的交换器(可以配置,默认同名),并且还会建立一个内部交换器federation:exchangeA->Broker B(其中Broker为集群名称)通过相同的绑定建进行绑定,于此同时Federation插件会建立一个federation:exchangeA->Broker B(BrokerB为集群名称),并且将内部交换器federation:exchangeA->Broker B绑定到该队列。
Federation插件会在队列federation:exchangeA->Broker B与BrokerA中的交换器exchangeA之间建立一条AMQP连接来实时地消费队列federation:exchangeA->Broker B中的数据。这些操作都是内部的,对外部业务客户端来说这条Federation link建立在BrokerA的exchangeA和BrokerB的exchangeA之间。
此时ClientB可以以较小的网络延迟向BrokerB的exchangeA发送消息,并且该消息会被正确路由到BrokerA中的exchangeA中,通过Federation插件我们可以以较小的网络延迟向与客户端属于不同地域的Broker节点发送消息。
“max_hops=1”表示一条消息最多被转发的次数为1。
默认的交换器(每个vhost下都会默认创建一个名为””的交换器)和内部交换器,不能对其使用Federation的功能。
联邦队列
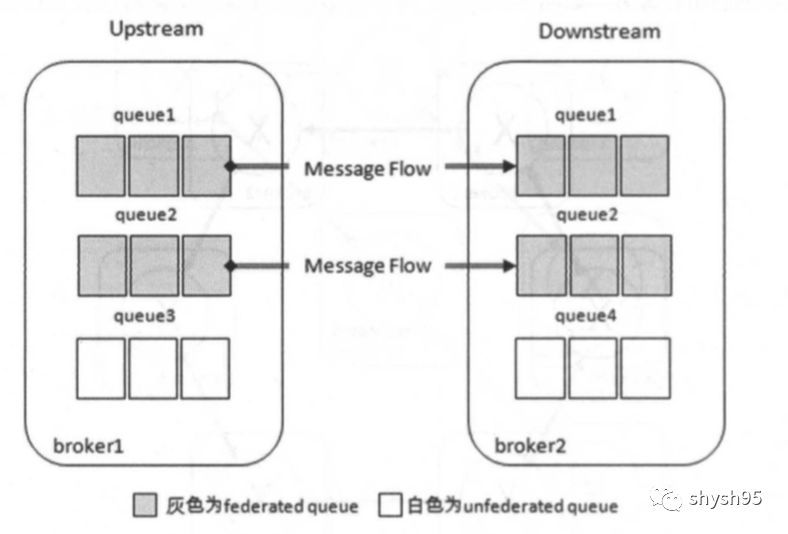
队列queue1和queue2原本在broker2中,由于某种需求将其配置为federated queue并将broker1作为upstream。Federation插件会在broker1上创建同名的队列queue1和queue2,与broker2中的队列queue1和queue2分别建立两条单向独立的Federation link。当有消费者ClientA连接broker2并通过Basic.Consume消费队列queue1(或queue2)中的消息时,如果队列queue1(或queue2)中本身有若干消息堆积,那么ClientA直接消费这些消息,此时broker2中的queue1(或queue2)并不会拉取broker1中的queue1(或queue2)的消息;如果队列queue1(或queue2)中没有消息堆积或者消息被消费完了,那么它会通过Federation link拉取在broker1中的上游队列queue1(或queue2)中的消息(如果有消息),然后存储到本地,之后再被消费者ClientA进行消费。
和federated exchange不同,一条消息可以在联邦队列间转发无限次。两个队列可以互为联邦队列。
如果两个队列互为联邦队列,队列中的消息除了被消费,还会转向有多余消费能力的一方,如果这种”多余的消费能力”在broker1和broker2中来回切换,那么消费也会在broker1和broker2中的队列queue中来回转发
federation queue只能使用Basic.Consume进行消费,并且不具备传递性。
参考文档:
https://cloud.tencent.com/developer/article/1469331
数据读写过程
存储原理
首先确认一个点,持久化和非持久化的消息都会落地磁盘,区别在于持久化的消息一定会写入磁盘(并且如果可以在内存中也会有一份),而非持久化的消息只有在内存吃紧的时候落地磁盘。两种类型消息的落盘都是在RabbitMQ的持久层中完成的。
RabbitMQ的持久层只是一个逻辑上的概念,实际包含两个部分:
- 队列索引(rabbit_queue_index):负责维护队列中落盘消息的信息,包括消息的存储地点、是否己被交付给消费者、是否己被消费者ack等。 每个队列都有与之对应的一个rabbit_queue_index
- 消息存储(rabbit_msg_store):以键值对的形式存储消息,它被所有vhost中的队列共享,在每个vhost中有且只有一个。rabbit_msg_store具体还可以分为 msg_store_persistent和msg_store_transient,msg_store_persistent负责持久化消息的持久化,重启后消息不会丢失;msg_store_transient负责 非持久化消息的持久化,重启后消息会丢失。
消息(包括消息体、属性和headers)可以直接存储在rabbit_queue_index中,也可以被保存在rabbit_msg_store中。
最佳的配备方式是较小的消息存储在rabbit_queue_index中而较大的信息则存储在rabbit_msg_store中。消息大小的参数可以通过queue_index_embed_mgs_below来配置,默认大小4096,单位B。
rabbit_queue_index中以顺序的段文件来开始存储,后缀为”.idx”,每个段文件中包含固定的SEGMENT_ENTRY_COUNT条记录,SEGMENT_ENTRY_COUNT默认值是16384。
经过rabbit_msg_store处理的所有消息都会以追加的方式写入到文件中,当一个文件的大小超过指定的限制(filesizelimit)后,关闭这个文件再创建一个新的文件以供新的消息写入。文件名(文件后缀是”.rdq”)从0开始进行累加,因此文件名最小的文件也是最老的文件。在进行消息的存储时,RabbitMQ会在ETS(Erlang Term Storage)表中记录消息在文件中的位置映射(Index)和文件的相关信息(FileSummary)。
在读取消息的时候,先根据消息的ID(msg id)找到对应存储的文件,如果文件存在并且未被锁住,则直接打开文件,从指定位置读取消息的内容。如果文件不存在或者被锁住了,则发送请求由rabbit_msg_store进行处理。
消息删除是只是删除ETS表中该消息的相关信息,同时更新消息对应的存储文件的相关信息。执行消息删除操作时,并不立即对文件中的消息进行删除,也就是说消息依然在文件中,仅仅是被标识为垃圾数据而已。一个文件中都是垃圾数据时可以将这个文件删除。当检测到前后两个文件中的有效数据可以合并在一个文件中,并且所有的垃圾数据的大小和所有文件(至少有3个文件存在的情况下)的数据大小的比值超过设置的阀值GARBAGE FRACTION(默认值为0.5)时才会触发垃圾回收将两个文件合并。
队列结构
通常队列由rabbit_amqpqueue_process和backing_queue两部分组成:
- rabbit_amqpqueue_process:负责协议相关的消息处理(即接收生产者发布的消息、向消费者交付消息、处理消息的确认(包括生产端的confirm和消费端的ack))等
- backing_queue:消息存储的具体形式和引擎,并向rabbit_amqpqueue_process提供接口以供调用
如果消息发送的队列是空的且队列有消费者,该消息不会经过该队列直接发往消费者,如果无法直接被消费,则需要将消息暂存入队列,以便重新投递。消息在存入队列后,主要有以下几种状态:
- alpha:消息内容(包括消息体、属性和headers)和消息索引都存在内存中
- beta:消息内容保存在磁盘中,消息索引都存在内存中
- gamma:消息内容保存在磁盘中,消息索引在磁盘和内存中都存在
- delta:消息内容和消息索引都在磁盘中
持久化的消息,消息内容和消息索引必须都保存在磁盘中,才会处于上面状态中的一种,gamma状态只有持久化的消息才有这种状态。
对于没有设置优先级和镜像的队列来说,backing_queue的默认实现是rabbit_variable_queue,其内部通过5个子队列来体现消息的各个状态:
- Q1:只包含alpha状态的消息
- Q2:包含beta和gamma的消息
- Delta:包含delta的消息
- Q3:包含beta和gamma的消息
- Q4:只包含alpha状态的消息
消息的状态一般变更方向是Q1->Q2->Delta->Q3->Q4,大体是从内存到磁盘然后再到内存中。
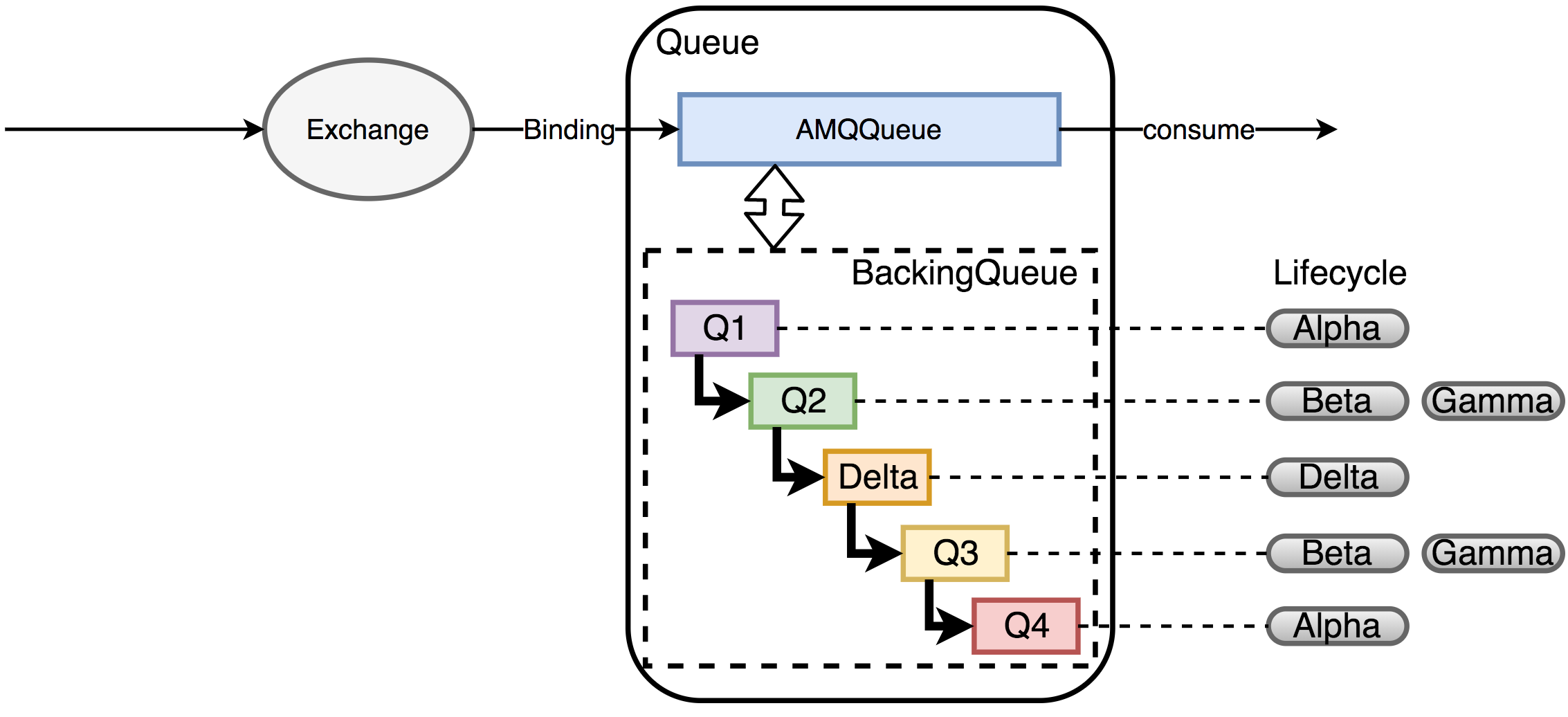
消费者消费消息也会引起消息状态的转换。
- 消费者消费时先从Q4获取消息,如果获取成功则返回。
- 如果Q4为空,则从Q3中获取消息,首先判断Q3是否为空,如果为空返回队列为空,即此时队列中无消息
- 如果Q3不为空,取出Q3的消息,然后判断Q3和Delta中的长度,如果都为空,那么Q2、Delta、Q3、Q4都为空,直接将Q1中的消息转移至Q4,下次直接从Q4中读取消息
- 如果Q3为空,Delta不为空,则将Delta中的消息转移至Q3中,下次直接从Q3中读取。
- 在将消息从Delta转移至Q3的过程中,是按照索引分段读取,首先读取某一段,然后判断读取的消息个数和Delta消息的个数,如果相等,判定Delta已无消息,直接将读取 Q2和读取到消息一并放入Q3,如果不相等,仅将此次读取的消息转移到Q3。
通常在负载正常时,如果消息被消费的速度不小于接收新消息的速度,对于不需要保证可靠不丢失的消息来说,极有可能只会处于alpha状态。对于durable属性设置为true的消息,它一定会进入gamma状态,并且在开启publisher confirm机制时,只有到了gamma状态时才会确认该消息己被接收,若消息消费速度足够快、内存也充足,这些消息也不会继续走到下一个状态。
这里以持久化消息为例(可以看到非持久化消息的生命周期会简单很多),从Q1到Q4,消息实际经历了一个RAM->DISK->RAM这样的过程,
BackingQueue的设计有点类似于Linux的虚拟内存Swap区,
- 当队列
负载很高时,通过将部分消息放到磁盘上来·节省内存空间`, - 当
负载降低时,消息又从磁盘回到内存中,让整个队列有很好的弹性。
因此触发消息流动的主要因素是:
消息被消费;内存不足。
- RabbitMQ会根据
消息的传输速度来计算当前内存中允许保存的最大消息数量(Traget_RAM_Count), - 当
内存中保存的消息数量 + 等待ACK的消息数量 > Target_RAM_Count时,RabbitMQ才会把消息写到磁盘上, - 所以说虽然理论上消息会按照
Q1->Q2->Delta->Q3->Q4的顺序流动,但是并不是每条消息都会经历所有的子队列以及对应的生命周期。 - 从RabbitMQ的Backing Queue结构来看,当
内存不足时,消息要经历多个生命周期,在Disk和RAM之间置换,这实际会降低RabbitMQ的处理性能(后续的流控就是关联的解决方法)。 - 对于持久化消息,RabbitMQ先将消息的内容和索引保存在磁盘中,然后才处于上面的某种状态(即只可能处于
alpha、gamma、delta三种状态之一)。
消息什么时候会刷到磁盘?
- 写入文件前会有一个
Buffer,大小为1M(1048576),数据在写入文件时,首先会写入到这个Buffer,如果Buffer已满,则会将Buffer写入到文件(未必刷到磁盘); - 有个
固定的刷盘时间:25ms,也就是不管Buffer满不满,每隔25ms,Buffer里的数据及未刷新到磁盘的文件内容必定会刷到磁盘; - 每次消息写入后,如果没有后续写入请求,则会直接将已写入的消息刷到磁盘:使用Erlang的
receive x after 0来实现,只要进程的信箱里没有消息,则产生一个timeout消息,而timeout会触发刷盘操作。
消息文件何时删除?
- 当所有文件中的垃圾消息(已经被删除的消息)比例大于阈值(
GARBAGE_FRACTION = 0.5)时,会触发文件合并操作(至少有三个文件存在的情况下),以提高磁盘利用率。 publish消息时写入内容,ack消息时删除内容(更新该文件的有用数据大小),当一个文件的有用数据等于0时,删除该文件。
参考文档:
http://geosmart.github.io/2019/11/11/RabbitMQ%E6%95%B0%E6%8D%AE%E8%AF%BB%E5%86%99%E8%BF%87%E7%A8%8B/
http://geosmart.github.io/2019/11/11/RabbitMQ%E6%95%B0%E6%8D%AE%E8%AF%BB%E5%86%99%E8%BF%87%E7%A8%8B/
https://cloud.tencent.com/developer/article/1469333
内存及磁盘告警
当内存使用超过配置的阈值或者磁盘剩余空间低于配置的阈值时,RabbitMQ会暂时阻塞客户端的连接并停止接收从客户端发来的消息。被阻塞的Connection的状态要么是blocking,要么是blocked,前者对应于并不试图发送消息的Connection,后者对应于一直有消息发送的Connection,这种状态下的Connection会被停止发送消息。注意在一个集群中,如果一个Broker节点的内存或者磁盘受限,都会引起整个集群中所有的Connection被阻塞。
内存告警
默认情况下内存阈值为0.4,表示当RabbitMQ使用的内存超过40%时,会产生内存告警并阻塞所有生产者的连接。一旦告警被解除(有消息被消费或者从内存转储到磁盘等情况的发生),一切都会恢复正常。
在某个Broker快达到内存阈值时,会先尝试将队列中的消息换页到磁盘以释放内存空间。默认情况下,在内存到达内存阈值的50%时会进行换页动作。
磁盘告警
当剩余磁盘空间低于确定的阈值时,RabbitMQ同样会阻塞生产者,这样可以避免因非持久化的消息持续换页而耗尽磁盘空间导致服务崩溃。默认情况下,磁盘阈值为50MB。RabbitMQ会定期检测磁盘剩余空间,检测的频率与上一次执行检测到的磁盘剩余空间大小有关,随着磁盘剩余空间与磁盘阈值的接近,检测频率会有所增加。
流控
- 当RabbitMQ出现内存(默认是0.4)或者磁盘资源达到阈值时,会触发流控机制:
阻塞Producer的Connection,让生产者不能继续发送消息,直到内存或者磁盘资源得到释放。 - Erlang进程之间并不共享内存(binaries类型除外),而是通过消息传递来通信,每个进程都有自己的进程邮箱。Erlang默认没有对进程邮箱大小设限制,所以当有大量消息持续发往某个进程时,会导致该进程邮箱过大,最终内存溢出并崩溃。
- 在RabbitMQ中,如果生产者持续高速发送,而消费者消费速度较低时,如果没有流控,很快就会使内部进程邮箱大小达到内存阈值,阻塞生产者(得益于block机制,并不会崩溃)。然后RabbitMQ会进行page操作,将内存中的数据持久化到磁盘中。
- 因此,要保证各个进程占用的内容在一个合理的范围,RabbitMQ的流控采用了一种信用机制(Credit),为每个进程维护了4类键值对:
{credit_from,From}-该值表示还能向消息接收进程From发送多少条消息;{credit_to,To}-表示当前进程再接收多少条消息,就要向消息发送进程增加Credit数量;credit_blocked-表示当前进程被哪些进程block了,比如进程A向B发送消息,那么当A的进程字典中{credit_from,B}的值为0是,那么A的credit_blocked值为[B];credit_deferred-消息接收进程向消息发送进程增加Credit的消息列表,当进程被Block时会记录消息信息,Unblock后依次发送这些消息;
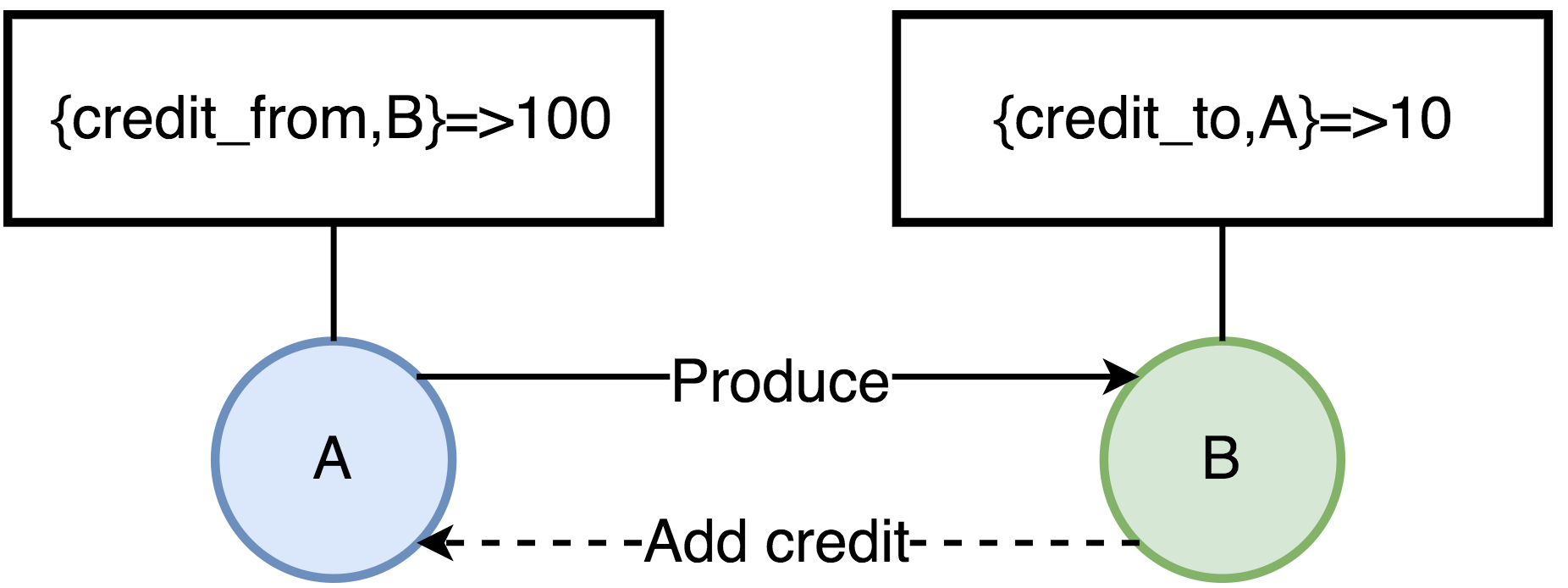
如图所示:
- A进程当前可以发送给B的消息有100条,每发一次,值减1,直到为0,A才会被Block住。
- B消费消息后,会给A增加新的Credit,这样A才可以持续的发送消息。
这里只画了两个进程,多进程串联的情况下,这中影响也就是从底向上传递的。
建议
- 避免队列过长
- 不要重复打开和关闭连接或者通道
- 不要在线程间共享通道
- 不要用太多的链接或者通道
- prefetch值设置要合理
- 不要忽略lazy queue
- 可以用TTL或者最大长度限制队列大小:如果吞吐量是优先级的话,可以通过从队列头部丢弃消息来保持队短
- 在底层节点上使用与核心数量一样多的队列(队列是单线程的)
- 持久化消息和队列
- 在不同内核上分割队列
- 队列性能仅 限于一个 CPU 核心。因此,如果您将队列拆分到不同的核心,并且如果您有一个 RabbitMQ 集群,那么您将获得更好的性能。
通过监控查看MQ线程负载
rabbitmq-diagnostics observer插件
下面这个插件我认为可能有点用处
consistent-hash-exchange
当一个队列被绑定到这个交换机上,它会更具他的绑定权重在一致哈希环上分配一个或者多个分区。 对于每个属性hash(例如routing_key),会被放置到相应的散列环分区。该分区对应于一个绑定队列,消息被路由到该队列。
假设publish的消息的routing_key是合理均匀的,那么被路由的消息应该均匀的分布在所有的环分区上,从而根据他们的绑定权重排队。
Q1 Rabbitmq集群的负载均衡是怎么做的 ?
A: Rabbitmq服务端本身是不支持负载均衡的,对于RabbitMQ集群来说,主要有两类负载均衡,客户端内部的和服务端的,客户端内部主要是采用负载均衡算法,服务端主要是采用代理服务器。服务端也可以用Haproxy作为负载均衡器。假设一个cluster里有两个实例,记作rabbitA和rabbitB。如果某个队列在rabbitA上创建,随后在rabbitB上镜像备份,那么rabbitA上的队列称为该队列的主队列(master queue),其它备份均为从队列。接下来,无论client访问rabbitA或rabbitB,最终消费的队列都是主队列。换句话说,即使在连接时主动连接rabbitB,RabbitMQ的cluster会自动把连接转向rabbitA。当且仅当rabbitA服务down掉以后,在剩余的从队列中再选举一个作为继任的主队列。出于这种机制而言, 负载均衡就不能简单的用随机化连接可以做到了
如果这种机制是真的,那么负载均衡就不能简单随机化连接就能做到了。需要满足下面的条件:
- 队列本身的建立需要随机化,即将队列分布于各个服务器;
- client访问需要知道每个队列的主队列保存在哪个服务器;
- 如果某个服务器down了,需要知道哪个从队列被选择成为继任的主队列。
于是,Load Balancing a RabbitMQ Cluster的作者给出了下图的结构。
这还是颇有点复杂的。首先,在建立一个新队列的时候,Randomiser会随机选择一个服务器,这样能够保证队列均匀分散在各个服务器(这里暂且不考虑负载)。建立队列后需要在Meta data里记录这个队列对应的服务器;另外,Monitor Service是关键,它用于处理某个服务器down掉的情况。一旦发生down机,它需要为之前主队列在该服务器的队列重新建立起与服务器的映射关系。
这里会遇到一个问题,即怎么判断某个队列的主队列呢?一个方法是通过rabbitmqctl,如下面的例子:
./rabbitmqctl -p production list_queues pid slave_pids
registration-email-queue <rabbit@mq01.2.1076.0> [<rabbit@mq00.1.285.0>]
registration-sms-queue <rabbit@mq01.2.1067.0> [<rabbit@mq00.1.281.0>]可以看到pid和slave_pids分别对应主队列所在的服务器和从服务器(可能有多个)。利用这个命令就可以了解每个队列所在的主服务器了。



